Caching is not a panacea
In this, the second in an occasional series on performance tuning, I want to explore why caching is not a panacea even though generally it is a good idea. For the first article in the series see Median v. Mean v. Total response time.
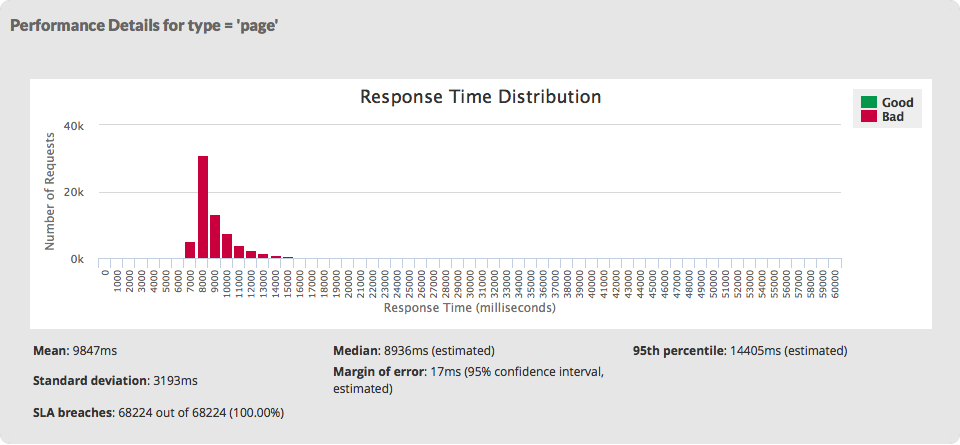
Consider the response-time distribution (or histogram) above. It shows the variation in response times for a set of real pages captured by WebTuna over the course of a day. There were just under 70,000 page requests made. The first thing to notice is the shape of the graph – it is a skewed distribution. There is a short, steep rise to a peak, followed by a relatively long tail. It is often described as a log-normal distribution and is typical of web applications (in fact, processing systems in general). So far, so good; nothing remarkable there.
The next thing to consider is visible range, which lies roughly between about 7000ms and 16,000ms. There are a few outliers beyond 16,000ms that are not visible at this scale. These are slow pages, by almost anybody’s definition. We have helpfully coloured the graph in red to highlight this. The acceptable threshold was defined as 5 seconds and none of the pages are meeting this target (the bars would be green if they did).
Below the graph we derive aggregated metrics that are easily understood, such as the mean and median. We can see that the average response time is just under 10 seconds, the median is just under 9 seconds. See my previous article on Median v. Mean v. Total response time on the meaning and significance of these figures. A page with an average response time of 10 seconds is not good. Any user requesting these pages is going to have to wait those 10 seconds (on average), and typically somewhere between 7 and 16 seconds. The pages are consistently slow. Your users are going to be consistently frustrated. As the website owner you would probably want to do something about it. This is where we get to the point of this article. One accepted method of speeding up a website is to introduce caching and this is what was done here. For our purposes, it doesn’t matter where the caching is introduced: whether it is at the browser, the web server, the application server, database or anywhere else. The point is that after caching was introduced the response-time distribution looked like this.
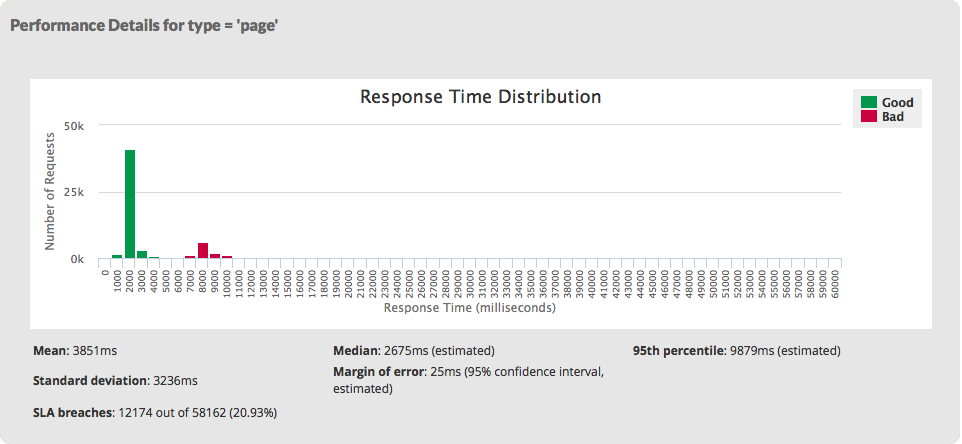
On this second occasion, we have roughly the same number of hits (just under 60,000) but the distribution is very different. There are two identifiable “humps" and that is because caching is never perfect. Here we achieved a cache hit rate of around 79%. There is still a rump of about 21% cache misses. As a consequence the mean has reduced from 9.8 to around 3.9 seconds (more than a factor of 2), whereas the median has reduced further from 8.9 to 2.7 seconds (a factor of 3). Overall, a good improvement has been made here.
But it is not quite as simple as that. The data you want may not always be in cache. The first person to request any particular piece of data has to get it from the origin, often a database. In that case they are likely to have to wait 7 to 11 seconds. It is subsequent users who benefit by having the result already cached. They are only likely to wait 2 to 3 seconds. The median is a good indicator of this. Very few people will actually wait for the average amount of time. So from any one user’s point of view the application is generally better but occasionally, for no good reason that they can see, the application is as bad as it used to be. They have gone from being consistently frustrated to sometimes frustrated but the frustration is still there. We can get a sense of that from the numbers: the standard deviation (the measure of variance) has hardly changed. Don’t get me wrong, caching is definitely a good idea if it improves overall performance but it is not a panacea. In this example, improving the cache hit ratio further might be worthwhile but there is definitely more work to be done to improve the non-cached response times.